Transcribing Large Audio Files with Next.js and Whisper
Recently, my team wanted to add a feature for users to upload audio files and then generate transcriptions from those files.
However, since audio files are large, I quickly discovered there are two main challenges.
1) There is a 25MB limit on our transcription API of choice (OpenAI Whisper). This translates to roughly an hour of audio - not enough for my use case.
2) Transcribing a one-hour audio file takes about 2-3 minutes. This is way too slow for my use case.
But, there’s good news - I’ll show you how I overcame both of these problems and how you can build your own system for users to upload audio and get transcriptions with Next.js.
Prerequisites
• Next.js project
• UploadThing account (or AWS S3 etc…)
• OpenAI key
• StreamPot API key
You can see the full code here
User File Uploads
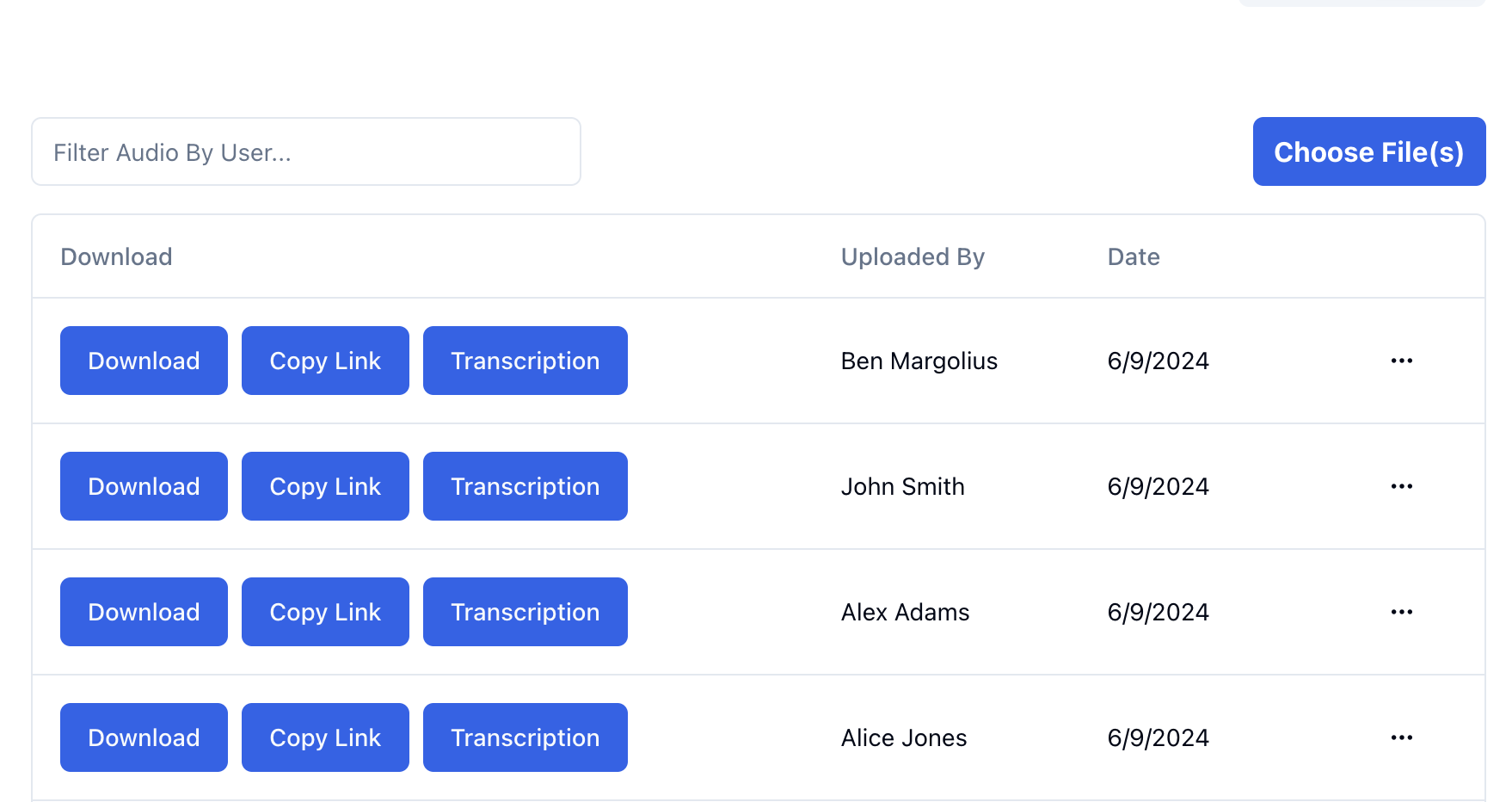
For user file uploads, I suggest UploadThing.
It’s stupidly-easy-to-use and comes with a bunch of nice Developer Experience (DX) features, such as pre-built Next.js components and easy hooks to trigger callbacks e.g. onBeforeUploadBegin, onClientUploadComplete and onUploadError.
To get UploadThing set up in your project, follow their quickstart guide.
Once you’ve got UploadThing set up in your project, add an audioUploader endpoint to the core.ts file (see UploadThing Quick Start).
// core.ts
export const ourFileRouter = {
audioUploader: f({ audio: { maxFileSize: "1GB", maxFileCount: 10 } })
.middleware(async ({ req }) => {
// middleware here
return { userId, name, projectId };
})
.onUploadComplete(async ({ metadata, file }) => {
// This code RUNS ON YOUR SERVER after upload
}),
} satisfies FileRouter;
In the example above, you’ll probably want to add some of your own functionality in the middlware function.
For example, you might want to fetch the user making the request from your database, and then pass that data to onUploadComplete. I didn’t show specifics here because the exact flow depends a lot on your Schema and Auth setup.
Once your audio uploads, the app creates a new Audio record in the database using the metadata received from UploadThing.
This way, the UI can update immediately to show the user their UploadedFile. You will also update this Audio record with the transcription once it’s generated!
// core.ts
export const ourFileRouter = {
audioUploader: f({ audio: { maxFileSize: "1GB", maxFileCount: 10 } })
.middleware(async ({ req }) => {
// middleware here
return { userId, name, projectId };
})
.onUploadComplete(async ({ metadata, file }) => {
const { userId, name, projectId } = metadata;
const audio = api.projects.addAudio({
projectId: projectId,
uploadedBy: userId,
uploadedByName: name,
audio: [
{
url: file.url,
key: file.key,
name: file.name,
type: file.type,
},
],
});
return { uploadedBy: metadata.userId, uploadedByName: metadata.name };
}),
} satisfies FileRouter;
Now that you have the audioUploader endpoint set up, it can be used in the frontend to handle the uploading of the file (using the UploadThing components).
// pages/index.tsx
import { ImageUp } from "lucide-react";
<UploadButton
endpoint="audioUploader"
headers={{
projectid: projectId,
}}
appearance={{ allowedContent: "hidden", button: "w-auto" }}
content={{
button: (
<>
<ImageUp className="mx-2 sm:hidden" size={24} />
<span className="hidden p-3 font-bold sm:inline">
Choose File(s)
</span>
</>
),
}}
className="w-fit"
onClientUploadComplete={async (res) => {
void utils.projects.getAudio.invalidate({ projectId });
toast({
title: "Audio uploaded successfully",
description:
"Your audio has been uploaded successfully. Please wait for a few seconds while the transcrption is being generated.",
});
await fetch("/api/transcrbie", {
method: "POST",
body: JSON.stringify({
audioURLs: res.map((file) => file.url),
}),
}).catch((error: Error) => {
toast({
title: "Error uploading audio",
description: error.message,
variant: "destructive",
});
});
toast({
title: "Audio transcrbied successfully",
description:
"Your audio has been transcribed successfully. Check your file for the transcription.",
});
await utils.projects.getAudio.invalidate({ projectId });
}}
onUploadError={(error: Error) => {
toast({
title: "Error uploading audio",
description: error.message,
variant: "destructive",
});
}}
/>
Let’s break down what this code does:
• The audioUploader endpoint from the first step handles the file upload.
• projectId is set in the headers when uploading to the audioUploader endpoint so that projectId can be used in the onUploadComplete callback to save the audio in the database.
• Appearance, Content, and className, are used to customize the UI of the UploadThing component to be mobile friendly.
• onClientUploadComplete is used to notify the user of the upload progress. Firstly, invalidate the getAudio query to force a re-fetch of the audio data. Next, hit the /transcribe endpoint (we’re about to create this in the next step) to transcribe the audio. Once the audio has transcribed the audio, invalidate the getAudio query again to force a re-fetch of the audio data - this time with the transcription.
Transcribing the audio
Firstly, create a new folder in src/app/api/ directory called transcribe. Inside this folder, create a new file called route.ts.
Now, remember the challenge I mentioned? 2-3 minutes per hour of upload is way too slow for long files. To solve this, we will chunk up our audio into segments and transcribe them separately.
How do we handle chunking up an audio file?
Well, my first thought was to use ffmpeg, a great tool for manipulating audio and video files on the backend.
The problem is, ffmpeg is really difficult to get working with Serverless, it’s a pretty bloated tool. It has to be in order to offer all the video manipulation features that it does. The problem is, it’s so big that it makes it very hard to use it in a serverless environment. So we’ll have to find a different way to handle this. Or do we…?
It turns out someone’s just solved this problem for us! A recent project that’s sprung up, called StreamPot, allows you to use ffmpeg by hitting their easy-to-use API. And it’s free! So we’ll use StreamPot to handle our audio chunking. Checkout their quickstart guide to get started, it’s super easy, it should take your less than 3 minutes to get it up and running in your project!
Once you have that set up, let’s get to creating our endpoint:
export const maxDuration = 180; // Make sure you're within the limits of your Vercel project
import openai from "@/lib/openai";
import { api } from "@/trpc/server";
import StreamPot from "@streampot/client";
import { NextResponse, type NextRequest } from "next/server";
import { type ChatCompletionMessage } from "openai/resources/index.mjs";
const streampot = new StreamPot({
secret: process.env.STREAMPOT_API_KEY,
});
const chunkJob = await streampot
.input(audioURL)
.outputOptions([
`-f segment`,
`-segment_time 300`, // Segment time in seconds, adjust if needed
`-segment_format mp3`,
`-segment_list_size 0`, // No maximum list size
`-segment_wrap 0`, // No wrapping
])
.output(`temp_%03d.mp3`)
.runAndWait();
let chunks: string[] = [];
if (chunkJob.status === "completed") {
chunks = Object.values(chunkJob.outputs);
} else {
throw new Error("StreamPot job failed: " + chunkJob.status);
}
const chunkTranscriptions = await Promise.allSettled(
chunks.map(async (chunkPath, index) => {
const file = await fetch(chunkPath);
const transcription = await openai.audio.transcriptions.create({
file: file,
model: "whisper-1",
temperature: 0,
prompt: prompt,
});
return transcription
? transcription.text
: `Failed to transcribe chunk ${index}`;
}),
);
return chunkTranscriptions
.map((result) => (result.status === "fulfilled" ? result.value : null))
.filter((text) => text !== null);
}
Let’s break down this chunkAndTranscribeAudio function:
The following code uses the StreamPot SDK to chunk the audio file into segments.
const chunkJob = await streampot
.input(audioURL)
.outputOptions([
`-f segment`,
`-segment_time 300`, // Segment time in seconds, adjust if needed
`-segment_format mp3`,
`-segment_list_size 0`, // No maximum list size
`-segment_wrap 0`, // No wrapping
])
.output(`temp_%03d.mp3`)
.runAndWait();
• The audioURL passed to .input is a url to download our audio file from. It’s the url we get from UploadThing.
• Within outputOptions , the important part is segment_time 300. This tells ffmpeg to split the audio into 300 second chunks. You can adjust the value depending on what tier you fall under for OpenAI’s Rate Limits. The smaller the chunks, the faster the transcription will be since the transcriptions are run concurrently using Promise.all. That said you can chew through your rate limits pretty quickly depending on how much audio is getting uploaded to your service. Do the math and pick a reasonable number here.
Next we send all of the chunks to OpenAI to be transcribed using the whisper-1 model.
const transcription = await openai.audio.transcriptions.create({
file: file,
model: "whisper-1",
temperature: 0,
prompt: prompt,
});
Once all the audio chunks are transcribed, we join them together into a single transcription.
As a bonus, I like to generate a summary of the transcription using GPT.
Then, we update the database with both the transcription and the summary.
//route.ts
//add the following below your imports
type Body = {
audioURLs: string[];
prompt?: string;
};
export async function POST(req: NextRequest): Promise<NextResponse> {
const body = (await req.json()) as Body;
const audioURLs = body.audioURLs;
const prompt = body.prompt ?? "Transcribe the following audio:";
const transcriptions = await Promise.allSettled(
audioURLs.map((audioURL) => chunkAndTranscribeAudio(audioURL, prompt)),
);
const joinedTranscription = (
transcriptions[0] as PromiseFulfilledResult<(string | null)[]>
).value?.join("\n");
const systemMessage: ChatCompletionMessage = {
role: "system",
content:
"You are an intelligent AI, your job is to create a 2-3 paragraph summary from a transcription of a conversation generated by Whisper.",
};
const response = await openai.chat.completions.create({
model: "gpt-4o",
temperature: 0,
messages: [
systemMessage,
{
role: "system",
content: "Transcription: " + joinedTranscription,
},
],
});
await api.projects.updateTranscription({
url: audioURLs[0] ?? "",
summary: response.choices[0]?.message.content ?? "",
transcription: joinedTranscription ?? "",
});
return new NextResponse(JSON.stringify({ message: "success" }), {
status: 200,
headers: {
"Content-Type": "application/json",
},
});
}
And that’s it!
We’ve made a Next.js serverless endpoint that transcribes audio files using Whisper and OpenAI’s completions API.
It’s a pretty simple setup, but it works well for me. I hope you find it useful too!